- жµПиІИ: 422042 жђ°
- жАІеИЂ:

- жЭ•иЗ™: жЭ≠еЈЮ
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (269)
- еОЯеИЫ (7)
- Java (51)
- Java Concurrency (2)
- IDE (16)
- Linux (46)
- Database (23)
- NoSQL (35)
- WebжЬНеК°еЩ® (23)
- LogжЧ•ењЧ (11)
- HTTP (11)
- HTML (2)
- XML (1)
- Test (7)
- Mina (0)
- Amoeba (4)
- Cobar (1)
- еЇПеИЧеМЦ (2)
- Python (5)
- PHP (1)
- SocketйАЪдњ° (1)
- Network (3)
- Struts (2)
- WebеЙНзЂѓ (10)
- Maven (6)
- SVN (15)
- Json (1)
- XMPP (2)
- Go (1)
- Other (4)
- жЬ™жХізРЖ (5)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2019-04 ( 1)
- 2018-07 ( 3)
- 2018-05 ( 1)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
u012374672пЉЪ
[color=darkred][/color][flash=2 ...
MongoзЪДORMж°ЖжЮґзЪДе≠¶дє†MorphiaпЉИannotationsпЉЙ -
b_l_eastпЉЪ
еЊИжЬЙйЧЃйҐШеХК
еИ©зФ®redisзЪДtransactionеКЯиГљпЉМеЃЮзО∞еИЖеЄГеЉПдЄЛеК†йФБ
жЫЊзїПз†Фз©ґињЗjkd1.5жЦ∞зЙєжАІпЉМеЕґдЄ≠ConcurrentHashMapе∞±жШѓеЕґдЄ≠дєЛдЄАпЉМеЕґзЙєзВєпЉЪжХИзОЗжѓФHashtableйЂШпЉМеєґеПСжАІжѓФhashmapе•љгАВзїУеРИдЇЖдЄ§иАЕзЪДзЙєзВєгАВ
¬†¬†¬†йЫЖеРИжШѓзЉЦз®ЛдЄ≠жЬАеЄЄзФ®зЪДжХ∞жНЃзїУжЮДгАВиАМи∞ИеИ∞еєґеПСпЉМеЗ†дєОжАїжШѓз¶їдЄНеЉАйЫЖеРИињЩз±їйЂШзЇІжХ∞жНЃзїУжЮДзЪДжФѓжМБгАВжѓФе¶ВдЄ§дЄ™зЇњз®ЛйЬАи¶БеРМжЧґиЃњйЧЃдЄАдЄ™дЄ≠йЧідЄізХМеМЇпЉИQueueпЉЙпЉМжѓФе¶ВеЄЄдЉЪзФ®зЉУе≠ШдљЬдЄЇе§ЦйГ®жЦЗдїґзЪДеЙѓжЬђпЉИHashMapпЉЙгАВињЩзѓЗжЦЗзЂ†дЄїи¶БеИЖжЮРjdk1.5зЪД3зІНеєґеПСйЫЖеРИз±їеЮЛпЉИconcurrentпЉМcopyonrightпЉМqueueпЉЙдЄ≠зЪДConcurrentHashMapпЉМиЃ©жИСдїђдїОеОЯзРЖдЄКзїЖиЗізЪДдЇЖиІ£еЃГдїђпЉМиГље§ЯиЃ©жИСдїђеЬ®жЈ±еЇ¶й°єзЫЃеЉАеПСдЄ≠иОЈзЫКйЭЮжµЕгАВ
 
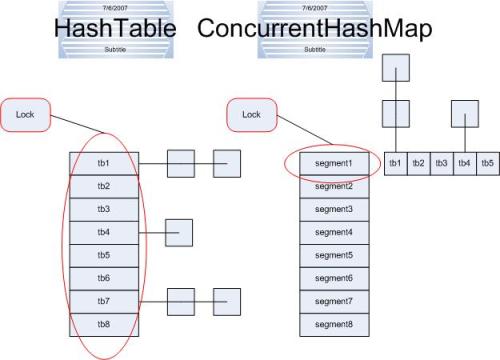
еЈ¶иЊєдЊњжШѓHashtableзЪДеЃЮзО∞жЦєеЉП---йФБжХідЄ™hashи°®пЉЫиАМеП≥иЊєеИЩжШѓConcurrentHashMapзЪДеЃЮзО∞жЦєеЉП---йФБж°ґпЉИжИЦжЃµпЉЙгАВ ¬† ConcurrentHashMapе∞Жhashи°®еИЖдЄЇ16дЄ™ж°ґпЉИйїШиЃ§еАЉпЉЙпЉМиѓЄе¶Вget,put,removeз≠ЙеЄЄзФ®жУНдљЬеП™йФБељУеЙНйЬАи¶БзФ®еИ∞зЪДж°ґгАВиѓХжГ≥пЉМеОЯжЭ• еП™иГљдЄАдЄ™зЇњз®ЛињЫеЕ•пЉМзО∞еЬ®еНіиГљеРМжЧґ16дЄ™еЖЩзЇњз®ЛињЫеЕ•пЉИеЖЩзЇњз®ЛжЙНйЬАи¶БйФБеЃЪпЉМиАМиѓїзЇњз®ЛеЗ†дєОдЄНеПЧйЩРеИґпЉМдєЛеРОдЉЪжПРеИ∞пЉЙпЉМеєґеПСжАІзЪДжПРеНЗжШѓжШЊиАМжШУиІБзЪДгАВ
- V get(Object key,  int  hash) {  
-     if  (count !=  0 ) {  // read-volatile   
-         HashEntry<K,V> e = getFirst(hash);  
-         while  (e !=  null ) {  
-             if  (e.hash == hash && key.equals(e.key)) {  
-                 V v = e.value;  
-                 if  (v !=  null )  
-                     return  v;  
-                 return  readValueUnderLock(e);  // recheck   
-             }  
-             e = e.next;  
-         }  
-     }  
-     return   null ;  
- }  
-   
- V readValueUnderLock(HashEntry<K,V> e) {  
-     lock();  
-     try  {  
-         return  e.value;  
-     } finally  {  
-         unlock();  
-     }  
- }  
put жУНдљЬдЄАдЄКжЭ•е∞±йФБеЃЪдЇЖжХідЄ™segmentпЉМињЩељУзДґжШѓдЄЇдЇЖеєґеПСзЪДеЃЙеЕ®пЉМдњЃжФєжХ∞жНЃжШѓдЄНиГљеєґеПСињЫи°МзЪД пЉМењЕй°їеЊЧжЬЙдЄ™еИ§жЦ≠жШѓеР¶иґЕйЩРзЪДиѓ≠еП•дї•з°ЃдњЭеЃєйЗПдЄНиґ≥жЧґиГље§Я rehashпЉМиАМжѓФиЊГйЪЊжЗВзЪДжШѓињЩеП•int index = hash & (tab.length - 1)пЉМеОЯжЭ•segmentйЗМйЭҐжЙНжШѓзЬЯж≠£зЪДhashtableпЉМеН≥жѓПдЄ™segmentжШѓдЄАдЄ™дЉ†зїЯжДПдєЙдЄКзЪДhashtable ,е¶ВдЄКеЫЊпЉМдїОдЄ§иАЕзЪДзїУжЮДе∞±еПѓдї•зЬЛеЗЇеМЇеИЂпЉМињЩйЗМе∞±жШѓжЙЊеЗЇйЬАи¶БзЪДentryеЬ®tableзЪДеУ™дЄАдЄ™дљНзљЃпЉМдєЛеРОеЊЧеИ∞зЪДentryе∞±жШѓињЩдЄ™йУЊзЪДзђђдЄАдЄ™иКВзВєпЉМе¶ВжЮЬe!=nullпЉМиѓіжШОжЙЊеИ∞дЇЖпЉМињЩжШѓе∞±и¶БжЫњжНҐиКВзВєзЪДеАЉпЉИonlyIfAbsent == falseпЉЙпЉМеР¶еИЩпЉМжИСдїђйЬАи¶БnewдЄАдЄ™entryпЉМеЃГзЪДеРОзїІжШѓfirstпЉМиАМиЃ©tab[index]жМЗеРСеЃГпЉМдїАдєИжДПжАЭеСҐпЉЯеЃЮйЩЕдЄКе∞±жШѓе∞ЖињЩдЄ™жЦ∞entry жПТеЕ•еИ∞йУЊе§іпЉМеЙ©дЄЛзЪДе∞±йЭЮеЄЄеЃєжШУзРЖиІ£дЇЖгАВ
- V put(K key,  int  hash, V value,  boolean  onlyIfAbsent) {  
-             lock();  
-             try  {  
-                 int  c = count;  
-                 if  (c++ > threshold)  // ensure capacity   
-                     rehash();  
-                 HashEntry<K,V>[] tab = table;  
-                 int  index = hash & (tab.length -  1 );  
-                 HashEntry<K,V> first = tab[index];  
-                 HashEntry<K,V> e = first;  
-                 while  (e !=  null  && (e.hash != hash || !key.equals(e.key)))  
-                     e = e.next;  
-   
-                 V oldValue;  
-                 if  (e !=  null ) {  
-                     oldValue = e.value;  
-                     if  (!onlyIfAbsent)  
-                         e.value = value;  
-                 }  
-                 else  {  
-                     oldValue = null ;  
-                     ++modCount;  
-                     tab[index] = new  HashEntry<K,V>(key, hash, first, value);  
-                     count = c; // write-volatile   
-                 }  
-                 return  oldValue;  
-             } finally  {  
-                 unlock();  
-             }  
-         }  
remove жУНдљЬйЭЮеЄЄз±їдЉЉputпЉМдљЖи¶Бж≥®жДПдЄАзВєеМЇеИЂпЉМдЄ≠йЧійВ£дЄ™forеЊ™зОѓжШѓеБЪдїАдєИзФ®зЪДеСҐпЉЯпЉИ*еПЈж†ЗиЃ∞пЉЙдїОдї£з†БжЭ•зЬЛпЉМе∞±жШѓе∞ЖеЃЪдљНдєЛеРОзЪДжЙАжЬЙentryеЕЛйЪЖеєґжЛЉеЫЮеЙНйЭҐеОїпЉМ дљЖжЬЙењЕи¶БеРЧпЉЯжѓПжђ°еИ†йЩ§дЄАдЄ™еЕГзі†е∞±и¶Бе∞ЖйВ£дєЛеЙНзЪДеЕГзі†еЕЛйЪЖдЄАйБНпЉЯињЩзВєеЕґеЃЮжШѓзФ±entryзЪДдЄНеПШжАІжЭ•еЖ≥еЃЪзЪДпЉМдїФзїЖиІВеѓЯentryеЃЪдєЙпЉМеПСзО∞йЩ§дЇЖvalueпЉМеЕґдїЦ жЙАжЬЙе±ЮжАІйГљжШѓзФ®finalжЭ•дњЃй•∞зЪДпЉМињЩжДПеС≥зЭАеЬ®зђђдЄАжђ°иЃЊзљЃдЇЖnextеЯЯдєЛеРОдЊњдЄНиГљеЖНжФєеПШеЃГпЉМеПЦиАМдї£дєЛзЪДжШѓе∞ЖеЃГдєЛеЙНзЪДиКВзВєеЕ®йГљеЕЛйЪЖдЄАжђ°гАВиЗ≥дЇОentryдЄЇдїАдєИи¶БиЃЊзљЃдЄЇдЄНеПШжАІпЉМињЩиЈЯдЄНеПШжАІзЪДиЃњйЧЃдЄНйЬАи¶БеРМж≠•дїОиАМиКВзЬБжЧґйЧіжЬЙеЕ≥пЉМеЕ≥дЇОдЄНеПШжАІзЪДжЫіе§ЪеЖЕеЃєпЉМиѓЈеПВйШЕдєЛеЙНзЪДжЦЗзЂ†гАКзЇњз®ЛйЂШзЇІ---зЇњз®ЛзЪДдЄАдЇЫзЉЦз®ЛжКАеЈІгАЛ
-     V remove(Object key,  int  hash, Object value) {  
-         lock();  
-         try  {  
-             int  c = count -  1 ;  
-             HashEntry<K,V>[] tab = table;  
-             int  index = hash & (tab.length -  1 );  
-             HashEntry<K,V> first = tab[index];  
-             HashEntry<K,V> e = first;  
-             while  (e !=  null  && (e.hash != hash || !key.equals(e.key)))  
-                 e = e.next;  
-   
-             V oldValue = null ;  
-             if  (e !=  null ) {  
-                 V v = e.value;  
-                 if  (value ==  null  || value.equals(v)) {  
-                     oldValue = v;  
-                     // All entries following removed node can stay   
-                     // in list, but all preceding ones need to be   
-                     // cloned.   
-                     ++modCount;  
-                     HashEntry<K,V> newFirst = e.next;  
-                     for  (HashEntry<K,V> p = first; p != e; p = p.next)  
-                         newFirst = new  HashEntry<K,V>(p.key, p.hash,  
-                                                       newFirst, p.value);  
-                     tab[index] = newFirst;  
-                     count = c; // write-volatile   
-                 }  
-             }  
-             return  oldValue;  
-         } finally  {  
-             unlock();  
-         }  
-     }  
-   
- static   final   class  HashEntry<K,V> {  
-     final  K key;  
-     final   int  hash;  
-     volatile  V value;  
-     final  HashEntry<K,V> next;  
-   
-     HashEntry(K key, int  hash, HashEntry<K,V> next, V value) {  
-         this .key = key;  
-         this .hash = hash;  
-         this .next = next;  
-         this .value = value;  
-     }  
-   
- гААгАА@SuppressWarnings ( "unchecked" )¬†¬†
- гААгААstatic ¬† final ¬†<K,V>¬†HashEntry<K,V>[]¬†newArray( int ¬†i)¬†{¬†¬†
- ¬†¬†¬†¬†гААгААreturn ¬† new ¬†HashEntry[i];¬†¬†
- гААгАА}¬†¬†
- }  
 
 
 
JavaеєґеПСзЉЦз®ЛдєЛConcurrentHashMap
 
 
ConcurrentHashMap
ConcurrentHashMapжШѓдЄАдЄ™зЇњз®ЛеЃЙеЕ®зЪДHash TableпЉМеЃГзЪДдЄїи¶БеКЯиГљжШѓжПРдЊЫдЇЖдЄАзїДеТМHashTableеКЯиГљзЫЄеРМдљЖжШѓзЇњз®ЛеЃЙеЕ®зЪДжЦєж≥ХгАВConcurrentHashMapеПѓдї•еБЪеИ∞иѓїеПЦжХ∞жНЃдЄНеК†йФБпЉМеєґдЄФеЕґеЖЕйГ®зЪДзїУжЮДеПѓдї•иЃ©еЕґеЬ®ињЫи°МеЖЩжУНдљЬзЪДжЧґеАЩиГље§Яе∞ЖйФБзЪДз≤ТеЇ¶дњЭжМБеЬ∞е∞љйЗПеЬ∞е∞ПпЉМдЄНзФ®еѓєжХідЄ™ConcurrentHashMapеК†йФБгАВ
ConcurrentHashMapзЪДеЖЕйГ®зїУжЮД
ConcurrentHashMapдЄЇдЇЖжПРйЂШжЬђиЇЂзЪДеєґеПСиГљеКЫпЉМеЬ®еЖЕйГ®йЗЗзФ®дЇЖдЄАдЄ™еПЂеБЪSegmentзЪДзїУжЮДпЉМдЄАдЄ™SegmentеЕґеЃЮе∞±жШѓдЄАдЄ™з±їHash TableзЪДзїУжЮДпЉМSegmentеЖЕйГ®зїіжК§дЇЖдЄАдЄ™йУЊи°®жХ∞зїДпЉМжИСдїђзФ®дЄЛйЭҐињЩдЄАеєЕеЫЊжЭ•зЬЛдЄЛConcurrentHashMapзЪДеЖЕйГ®зїУжЮДпЉЪ
дїОдЄКйЭҐзЪДзїУжЮДжИСдїђеПѓдї•дЇЖиІ£еИ∞пЉМConcurrentHashMapеЃЪдљНдЄАдЄ™еЕГзі†зЪДињЗз®ЛйЬАи¶БињЫи°МдЄ§жђ°HashжУНдљЬпЉМзђђдЄАжђ°HashеЃЪдљНеИ∞SegmentпЉМзђђдЇМжђ°HashеЃЪдљНеИ∞еЕГзі†жЙАеЬ®зЪДйУЊи°®зЪДе§ійГ®пЉМеЫ†ж≠§пЉМињЩдЄАзІНзїУжЮДзЪДеЄ¶жЭ•зЪДеЙѓдљЬзФ®жШѓHashзЪДињЗз®Ли¶БжѓФжЩЃйАЪзЪДHashMapи¶БйХњпЉМдљЖжШѓеЄ¶жЭ•зЪДе•ље§ДжШѓеЖЩжУНдљЬзЪДжЧґеАЩеПѓдї•еП™еѓєеЕГзі†жЙАеЬ®зЪДSegmentињЫи°МеК†йФБеН≥еПѓпЉМдЄНдЉЪељ±еУНеИ∞еЕґдїЦзЪДSegmentпЉМињЩж†ЈпЉМеЬ®жЬАзРЖжГ≥зЪДжГЕеЖµдЄЛпЉМConcurrentHashMapеПѓдї•жЬАйЂШеРМжЧґжФѓжМБSegmentжХ∞йЗПе§Іе∞ПзЪДеЖЩжУНдљЬпЉИеИЪе•љињЩдЇЫеЖЩжУНдљЬйГљйЭЮеЄЄеє≥еЭЗеЬ∞еИЖеЄГеЬ®жЙАжЬЙзЪДSegmentдЄКпЉЙпЉМжЙАдї•пЉМйАЪињЗињЩдЄАзІНзїУжЮДпЉМConcurrentHashMapзЪДеєґеПСиГљеКЫеПѓдї•е§Іе§ІзЪДжПРйЂШгАВ
Segment
жИСдїђеЖНжЭ•еЕЈдљУдЇЖиІ£дЄАдЄЛSegmentзЪДжХ∞жНЃзїУжЮДпЉЪ
 
- static   final   class  Segment<K,V>  extends  ReentrantLock  implements  Serializable {  
-     transient   volatile   int  count;  
-     transient   int  modCount;  
-     transient   int  threshold;  
-     transient   volatile  HashEntry<K,V>[] table;  
-     final   float  loadFactor;  
- }  
 
 
иѓ¶зїЖиІ£йЗКдЄАдЄЛSegmentйЗМйЭҐзЪДжИРеСШеПШйЗПзЪДжДПдєЙпЉЪ
- countпЉЪSegmentдЄ≠еЕГзі†зЪДжХ∞йЗП
- modCountпЉЪеѓєtableзЪДе§Іе∞ПйА†жИРељ±еУНзЪДжУНдљЬзЪДжХ∞йЗПпЉИжѓФе¶ВputжИЦиАЕremoveжУНдљЬпЉЙ
- thresholdпЉЪйШИеАЉпЉМSegmentйЗМйЭҐеЕГзі†зЪДжХ∞йЗПиґЕињЗињЩдЄ™еАЉдЊЭжЧІе∞±дЉЪеѓєSegmentињЫи°МжЙ©еЃє
- tableпЉЪйУЊи°®жХ∞зїДпЉМжХ∞зїДдЄ≠зЪДжѓПдЄАдЄ™еЕГзі†дї£и°®дЇЖдЄАдЄ™йУЊи°®зЪДе§ійГ®
- loadFactorпЉЪиіЯиљљеЫ†е≠РпЉМзФ®дЇОз°ЃеЃЪthreshold
HashEntry
SegmentдЄ≠зЪДеЕГзі†жШѓдї•HashEntryзЪД嚥еЉПе≠ШжФЊеЬ®йУЊи°®жХ∞зїДдЄ≠зЪДпЉМзЬЛдЄАдЄЛHashEntryзЪДзїУжЮДпЉЪ
 
- static   final   class  HashEntry<K,V> {  
-     final  K key;  
-     final   int  hash;  
-     volatile  V value;  
-     final  HashEntry<K,V> next;  
- }  
 
еПѓдї•зЬЛеИ∞HashEntryзЪДдЄАдЄ™зЙєзВєпЉМйЩ§дЇЖvalueдї•е§ЦпЉМеЕґдїЦзЪДеЗ†дЄ™еПШйЗПйГљжШѓfinalзЪДпЉМињЩж†ЈеБЪжШѓдЄЇдЇЖйШ≤ж≠ҐйУЊи°®зїУжЮД襀熳еЭПпЉМеЗЇзО∞ConcurrentModificationзЪДжГЕеЖµгАВ
ConcurrentHashMapзЪДеИЭеІЛеМЦ
дЄЛйЭҐжИСдїђжЭ•зїУеРИжЇРдї£з†БжЭ•еЕЈдљУеИЖжЮРдЄАдЄЛConcurrentHashMapзЪДеЃЮзО∞пЉМеЕИзЬЛдЄЛеИЭеІЛеМЦжЦєж≥ХпЉЪ
 
- public  ConcurrentHashMap( int  initialCapacity,  
-                          float  loadFactor,  int  concurrencyLevel) {  
-     if  (!(loadFactor >  0 ) || initialCapacity <  0  || concurrencyLevel <=  0 )  
-         throw   new  IllegalArgumentException();  
-    
-     if  (concurrencyLevel > MAX_SEGMENTS)  
-         concurrencyLevel = MAX_SEGMENTS;  
-    
-     // Find power-of-two sizes best matching arguments   
-     int  sshift =  0 ;  
-     int  ssize =  1 ;  
-     while  (ssize < concurrencyLevel) {  
-         ++sshift;  
-         ssize <<= 1 ;  
-     }  
-     segmentShift = 32  - sshift;  
-     segmentMask = ssize - 1 ;  
-     this .segments = Segment.newArray(ssize);  
-    
-     if  (initialCapacity > MAXIMUM_CAPACITY)  
-         initialCapacity = MAXIMUM_CAPACITY;  
-     int  c = initialCapacity / ssize;  
-     if  (c * ssize < initialCapacity)  
-         ++c;  
-     int  cap =  1 ;  
-     while  (cap < c)  
-         cap <<= 1 ;  
-    
-     for  ( int  i =  0 ; i <  this .segments.length; ++i)  
-         this .segments[i] =  new  Segment<K,V>(cap, loadFactor);  
- }  
 
CurrentHashMapзЪДеИЭеІЛеМЦдЄАеЕ±жЬЙдЄЙдЄ™еПВжХ∞пЉМдЄАдЄ™initialCapacityпЉМи°®з§ЇеИЭеІЛзЪДеЃєйЗПпЉМдЄАдЄ™loadFactorпЉМи°®з§ЇиіЯиљљеПВжХ∞пЉМжЬАеРОдЄАдЄ™жШѓconcurrentLevelпЉМдї£и°®ConcurrentHashMapеЖЕйГ®зЪДSegmentзЪДжХ∞йЗПпЉМConcurrentLevelдЄАзїПжМЗеЃЪпЉМдЄНеПѓжФєеПШпЉМеРОзї≠е¶ВжЮЬConcurrentHashMapзЪДеЕГзі†жХ∞йЗПеҐЮеК†еѓЉиЗіConrruentHashMapйЬАи¶БжЙ©еЃєпЉМConcurrentHashMapдЄНдЉЪеҐЮеК†SegmentзЪДжХ∞йЗПпЉМиАМеП™дЉЪеҐЮеК†SegmentдЄ≠йУЊи°®жХ∞зїДзЪДеЃєйЗПе§Іе∞ПпЉМињЩж†ЈзЪДе•ље§ДжШѓжЙ©еЃєињЗз®ЛдЄНйЬАи¶БеѓєжХідЄ™ConcurrentHashMapеБЪrehashпЉМиАМеП™йЬАи¶БеѓєSegmentйЗМйЭҐзЪДеЕГзі†еБЪдЄАжђ°rehashе∞±еПѓдї•дЇЖгАВ
жХідЄ™ConcurrentHashMapзЪДеИЭеІЛеМЦжЦєж≥ХињШжШѓйЭЮеЄЄзЃАеНХзЪДпЉМеЕИжШѓж†єжНЃconcurrentLevelжЭ•newеЗЇSegmentпЉМињЩйЗМSegmentзЪДжХ∞йЗПжШѓдЄНе§ІдЇОconcurrentLevelзЪДжЬАе§ІзЪД2зЪДжМЗжХ∞пЉМе∞±жШѓиѓіSegmentзЪДжХ∞йЗПж∞ЄињЬжШѓ2зЪДжМЗжХ∞дЄ™пЉМињЩж†ЈзЪДе•ље§ДжШѓжЦєдЊњйЗЗзФ®зІїдљНжУНдљЬжЭ•ињЫи°МhashпЉМеК†ењЂhashзЪДињЗз®ЛгАВжО•дЄЛжЭ•е∞±жШѓж†єжНЃintialCapacityз°ЃеЃЪSegmentзЪДеЃєйЗПзЪДе§Іе∞ПпЉМжѓПдЄАдЄ™SegmentзЪДеЃєйЗПе§Іе∞ПдєЯжШѓ2зЪДжМЗжХ∞пЉМеРМж†ЈдљњдЄЇдЇЖеК†ењЂhashзЪДињЗз®ЛгАВ
ињЩиЊєйЬАи¶БзЙєеИЂж≥®жДПдЄАдЄЛдЄ§дЄ™еПШйЗПпЉМеИЖеИЂжШѓsegmentShiftеТМsegmentMaskпЉМињЩдЄ§дЄ™еПШйЗПеЬ®еРОйЭҐе∞ЖдЉЪиµЈеИ∞еЊИе§ІзЪДдљЬзФ®пЉМеБЗиЃЊжЮДйА†еЗљжХ∞з°ЃеЃЪдЇЖSegmentзЪДжХ∞йЗПжШѓ2зЪДnжђ°жЦєпЉМйВ£дєИsegmentShiftе∞±з≠ЙдЇО32еЗПеОїnпЉМиАМsegmentMaskе∞±з≠ЙдЇО2зЪДnжђ°жЦєеЗПдЄАгАВ
ConcurrentHashMapзЪДgetжУНдљЬ
еЙНйЭҐжПРеИ∞ињЗConcurrentHashMapзЪДgetжУНдљЬжШѓдЄНзФ®еК†йФБзЪДпЉМжИСдїђињЩйЗМзЬЛдЄАдЄЛеЕґеЃЮзО∞пЉЪ
 
- public  V get(Object key) {  
-     int  hash = hash(key.hashCode());  
-     return  segmentFor(hash).get(key, hash);  
- }  
 
зЬЛзђђдЄЙи°МпЉМsegmentForињЩдЄ™еЗљжХ∞зФ®дЇОз°ЃеЃЪжУНдљЬеЇФиѓ•еЬ®еУ™дЄАдЄ™segmentдЄ≠ињЫи°МпЉМеЗ†дєОеѓєConcurrentHashMapзЪДжЙАжЬЙжУНдљЬйГљйЬАи¶БзФ®еИ∞ињЩдЄ™еЗљжХ∞пЉМжИСдїђзЬЛдЄЛињЩдЄ™еЗљжХ∞зЪДеЃЮзО∞пЉЪ
 
- final  Segment<K,V> segmentFor( int  hash) {  
-     return  segments[(hash >>> segmentShift) & segmentMask];  
- }  
 
ињЩдЄ™еЗљжХ∞зФ®дЇЖдљНжУНдљЬжЭ•з°ЃеЃЪSegmentпЉМж†єжНЃдЉ†еЕ•зЪДhashеАЉеРСеП≥жЧ†зђ¶еПЈеП≥зІїsegmentShiftдљНпЉМзДґеРОеТМsegmentMaskињЫи°МдЄОжУНдљЬпЉМзїУеРИжИСдїђдєЛеЙНиѓізЪДsegmentShiftеТМsegmentMaskзЪДеАЉпЉМе∞±еПѓдї•еЊЧеЗЇдї•дЄЛзїУиЃЇпЉЪеБЗиЃЊSegmentзЪДжХ∞йЗПжШѓ2зЪДnжђ°жЦєпЉМж†єжНЃеЕГзі†зЪДhashеАЉзЪДйЂШnдљНе∞±еПѓдї•з°ЃеЃЪеЕГзі†еИ∞еЇХеЬ®еУ™дЄАдЄ™SegmentдЄ≠гАВ
еЬ®з°ЃеЃЪдЇЖйЬАи¶БеЬ®еУ™дЄАдЄ™segmentдЄ≠ињЫи°МжУНдљЬдї•еРОпЉМжО•дЄЛжЭ•зЪДдЇЛжГЕе∞±жШѓи∞ГзФ®еѓєеЇФзЪДSegmentзЪДgetжЦєж≥ХпЉЪ
 
- V get(Object key,  int  hash) {  
-     if  (count !=  0 ) {  // read-volatile   
-         HashEntry<K,V> e = getFirst(hash);  
-         while  (e !=  null ) {  
-             if  (e.hash == hash && key.equals(e.key)) {  
-                 V v = e.value;  
-                 if  (v !=  null )  
-                     return  v;  
-                 return  readValueUnderLock(e);  // recheck   
-             }  
-             e = e.next;  
-         }  
-     }  
-     return   null ;  
- }  
 
еЕИзЬЛзђђдЇМи°Мдї£з†БпЉМињЩйЗМеѓєcountињЫи°МдЇЖдЄАжђ°еИ§жЦ≠пЉМеЕґдЄ≠countи°®з§ЇSegmentдЄ≠еЕГзі†зЪДжХ∞йЗПпЉМжИСдїђеПѓдї•жЭ•зЬЛдЄАдЄЛcountзЪДеЃЪдєЙпЉЪ
 
- transient   volatile   int  count;  
 
еПѓдї•зЬЛеИ∞countжШѓvolatileзЪДпЉМеЃЮйЩЕдЄКињЩйЗМйЗМйЭҐеИ©зФ®дЇЖvolatileзЪДиѓ≠дєЙпЉЪ
 
еЫ†дЄЇеЃЮйЩЕдЄКputгАБremoveз≠ЙжУНдљЬдєЯдЉЪжЫіжЦ∞countзЪДеАЉпЉМжЙАдї•ељУзЂЮдЇЙеПСзФЯзЪДжЧґеАЩпЉМvolatileзЪДиѓ≠дєЙеПѓдї•дњЭиѓБеЖЩжУНдљЬеЬ®иѓїжУНдљЬдєЛеЙНпЉМдєЯе∞±дњЭиѓБдЇЖеЖЩжУНдљЬеѓєеРОзї≠зЪДиѓїжУНдљЬйГљжШѓеПѓиІБзЪДпЉМињЩж†ЈеРОйЭҐgetзЪДеРОзї≠жУНдљЬе∞±еПѓдї•жЛњеИ∞еЃМжХізЪДеЕГзі†еЖЕеЃєгАВ
зДґеРОпЉМеЬ®зђђдЄЙи°МпЉМи∞ГзФ®дЇЖgetFirst()жЭ•еПЦеЊЧйУЊи°®зЪДе§ійГ®пЉЪ
 
- HashEntry<K,V> getFirst( int  hash) {  
-     HashEntry<K,V>[] tab = table;  
-     return  tab[hash & (tab.length -  1 )];  
- }  
 
еРМж†ЈпЉМињЩйЗМдєЯжШѓзФ®дљНжУНдљЬжЭ•з°ЃеЃЪйУЊи°®зЪДе§ійГ®пЉМhashеАЉеТМHashTableзЪДйХњеЇ¶еЗПдЄАеБЪдЄОжУНдљЬпЉМжЬАеРОзЪДзїУжЮЬе∞±жШѓhashеАЉзЪДдљОnдљНпЉМеЕґдЄ≠nжШѓHashTableзЪДйХњеЇ¶дї•2дЄЇеЇХзЪДзїУжЮЬгАВ
еЬ®з°ЃеЃЪдЇЖйУЊи°®зЪДе§ійГ®дї•еРОпЉМе∞±еПѓдї•еѓєжХідЄ™йУЊи°®ињЫи°МйБНеОЖпЉМзЬЛзђђ4и°МпЉМеПЦеЗЇkeyеѓєеЇФзЪДvalueзЪДеАЉпЉМе¶ВжЮЬжЛњеЗЇзЪДvalueзЪДеАЉжШѓnullпЉМеИЩеПѓиГљињЩдЄ™keyпЉМvalueеѓєж≠£еЬ®putзЪДињЗз®ЛдЄ≠пЉМе¶ВжЮЬеЗЇзО∞ињЩзІНжГЕеЖµпЉМйВ£дєИе∞±еК†йФБжЭ•дњЭиѓБеПЦеЗЇзЪДvalueжШѓеЃМжХізЪДпЉМе¶ВжЮЬдЄНжШѓnullпЉМеИЩзЫіжО•ињФеЫЮvalueгАВ
ConcurrentHashMapзЪДputжУНдљЬ
зЬЛеЃМдЇЖgetжУНдљЬпЉМеЖНзЬЛдЄЛputжУНдљЬпЉМputжУНдљЬзЪДеЙНйЭҐдєЯжШѓз°ЃеЃЪSegmentзЪДињЗз®ЛпЉМињЩйЗМдЄНеЖНиµШињ∞пЉМзЫіжО•зЬЛеЕ≥йФЃзЪДsegmentзЪДputжЦєж≥ХпЉЪ
 
- V put(K key,  int  hash, V value,  boolean  onlyIfAbsent) {  
-     lock();  
-     try  {  
-         int  c = count;  
-         if  (c++ > threshold)  // ensure capacity   
-             rehash();  
-         HashEntry<K,V>[] tab = table;  
-         int  index = hash & (tab.length -  1 );  
-         HashEntry<K,V> first = tab[index];  
-         HashEntry<K,V> e = first;  
-         while  (e !=  null  && (e.hash != hash || !key.equals(e.key)))  
-             e = e.next;  
-    
-         V oldValue;  
-         if  (e !=  null ) {  
-             oldValue = e.value;  
-             if  (!onlyIfAbsent)  
-                 e.value = value;  
-         }  
-         else  {  
-             oldValue = null ;  
-             ++modCount;  
-             tab[index] = new  HashEntry<K,V>(key, hash, first, value);  
-             count = c; // write-volatile   
-         }  
-         return  oldValue;  
-     } finally  {  
-         unlock();  
-     }  
- }  
 
й¶ЦеЕИеѓєSegmentзЪДputжУНдљЬжШѓеК†йФБеЃМжИРзЪДпЉМзДґеРОеЬ®зђђдЇФи°МпЉМе¶ВжЮЬSegmentдЄ≠еЕГзі†зЪДжХ∞йЗПиґЕињЗдЇЖйШИеАЉпЉИзФ±жЮДйА†еЗљжХ∞дЄ≠зЪДloadFactorзЃЧеЗЇпЉЙињЩйЬАи¶БињЫи°МеѓєSegmentжЙ©еЃєпЉМеєґдЄФи¶БињЫи°МrehashпЉМеЕ≥дЇОrehashзЪДињЗз®Ле§ІеЃґеПѓдї•иЗ™еЈ±еОїдЇЖиІ£пЉМињЩйЗМдЄНиѓ¶зїЖиЃ≤дЇЖгАВ
зђђ8еТМзђђ9и°МзЪДжУНдљЬе∞±жШѓgetFirstзЪДињЗз®ЛпЉМз°ЃеЃЪйУЊи°®е§ійГ®зЪДдљНзљЃгАВ
зђђ11и°МињЩйЗМзЪДињЩдЄ™whileеЊ™зОѓжШѓеЬ®йУЊи°®дЄ≠еѓїжЙЊеТМи¶БputзЪДеЕГзі†зЫЄеРМkeyзЪДеЕГзі†пЉМе¶ВжЮЬжЙЊеИ∞пЉМе∞±зЫіжО•жЫіжЦ∞жЫіжЦ∞keyзЪДvalueпЉМе¶ВжЮЬж≤°жЬЙжЙЊеИ∞пЉМеИЩињЫеЕ•21и°МињЩйЗМпЉМзФЯжИРдЄАдЄ™жЦ∞зЪДHashEntryеєґдЄФжККеЃГеК†еИ∞жХідЄ™SegmentзЪДе§ійГ®пЉМзДґеРОеЖНжЫіжЦ∞countзЪДеАЉгАВ
ConcurrentHashMapзЪДremoveжУНдљЬ
RemoveжУНдљЬзЪДеЙНйЭҐдЄАйГ®еИЖеТМеЙНйЭҐзЪДgetеТМputжУНдљЬдЄАж†ЈпЉМйГљжШѓеЃЪдљНSegmentзЪДињЗз®ЛпЉМзДґеРОеЖНи∞ГзФ®SegmentзЪДremoveжЦєж≥ХпЉЪ
 
- V remove(Object key,  int  hash, Object value) {  
-     lock();  
-     try  {  
-         int  c = count -  1 ;  
-         HashEntry<K,V>[] tab = table;  
-         int  index = hash & (tab.length -  1 );  
-         HashEntry<K,V> first = tab[index];  
-         HashEntry<K,V> e = first;  
-         while  (e !=  null  && (e.hash != hash || !key.equals(e.key)))  
-             e = e.next;  
-    
-         V oldValue = null ;  
-         if  (e !=  null ) {  
-             V v = e.value;  
-             if  (value ==  null  || value.equals(v)) {  
-                 oldValue = v;  
-                 // All entries following removed node can stay   
-                 // in list, but all preceding ones need to be   
-                 // cloned.   
-                 ++modCount;  
-                 HashEntry<K,V> newFirst = e.next;  
-                 for  (HashEntry<K,V> p = first; p != e; p = p.next)  
-                     newFirst = new  HashEntry<K,V>(p.key, p.hash,  
-                                                   newFirst, p.value);  
-                 tab[index] = newFirst;  
-                 count = c; // write-volatile   
-             }  
-         }  
-         return  oldValue;  
-     } finally  {  
-         unlock();  
-     }  
- }  
 
й¶ЦеЕИremoveжУНдљЬдєЯжШѓз°ЃеЃЪйЬАи¶БеИ†йЩ§зЪДеЕГзі†зЪДдљНзљЃпЉМдЄНињЗињЩйЗМеИ†йЩ§еЕГзі†зЪДжЦєж≥ХдЄНжШѓзЃАеНХеЬ∞жККеЊЕеИ†йЩ§еЕГзі†зЪДеЙНйЭҐзЪДдЄАдЄ™еЕГзі†зЪДnextжМЗеРСеРОйЭҐдЄАдЄ™е∞±еЃМдЇЛдЇЖпЉМжИСдїђдєЛеЙНеЈ≤зїПиѓіињЗHashEntryдЄ≠зЪДnextжШѓfinalзЪДпЉМдЄАзїПиµЛеАЉдї•еРОе∞±дЄНеПѓдњЃжФєпЉМеЬ®еЃЪдљНеИ∞еЊЕеИ†йЩ§еЕГзі†зЪДдљНзљЃдї•еРОпЉМз®ЛеЇПе∞±е∞ЖеЊЕеИ†йЩ§еЕГзі†еЙНйЭҐзЪДйВ£дЄАдЇЫеЕГзі†еЕ®йГ®е§НеИґдЄАйБНпЉМзДґеРОеЖНдЄАдЄ™дЄАдЄ™йЗНжЦ∞жО•еИ∞йУЊи°®дЄКеОїпЉМзЬЛдЄАдЄЛдЄЛйЭҐињЩдЄАеєЕеЫЊжЭ•дЇЖиІ£ињЩдЄ™ињЗз®ЛпЉЪ
еБЗиЃЊйУЊи°®дЄ≠еОЯжЭ•зЪДеЕГзі†е¶ВдЄКеЫЊжЙАз§ЇпЉМзО∞еЬ®и¶БеИ†йЩ§еЕГзі†3пЉМйВ£дєИеИ†йЩ§еЕГзі†3дї•еРОзЪДйУЊи°®е∞±е¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
ConcurrentHashMapзЪДsizeжУНдљЬ
еЬ®еЙНйЭҐзЪДзЂ†иКВдЄ≠пЉМжИСдїђжґЙеПКеИ∞зЪДжУНдљЬйГљжШѓеЬ®еНХдЄ™SegmentдЄ≠ињЫи°МзЪДпЉМдљЖжШѓConcurrentHashMapжЬЙдЄАдЇЫжУНдљЬжШѓеЬ®е§ЪдЄ™SegmentдЄ≠ињЫи°МпЉМжѓФе¶ВsizeжУНдљЬпЉМConcurrentHashMapзЪДsizeжУНдљЬдєЯйЗЗзФ®дЇЖдЄАзІНжѓФиЊГеЈІзЪДжЦєеЉПпЉМжЭ•е∞љйЗПйБњеЕНеѓєжЙАжЬЙзЪДSegmentйГљеК†йФБгАВ
еЙНйЭҐжИСдїђжПРеИ∞дЇЖдЄАдЄ™SegmentдЄ≠зЪДжЬЙдЄАдЄ™modCountеПШйЗПпЉМдї£и°®зЪДжШѓеѓєSegmentдЄ≠еЕГзі†зЪДжХ∞йЗПйА†жИРељ±еУНзЪДжУНдљЬзЪДжђ°жХ∞пЉМињЩдЄ™еАЉеП™еҐЮдЄНеЗПпЉМsizeжУНдљЬе∞±жШѓйБНеОЖдЇЖдЄ§жђ°SegmentпЉМжѓПжђ°иЃ∞ељХSegmentзЪДmodCountеАЉпЉМзДґеРОе∞ЖдЄ§жђ°зЪДmodCountињЫи°МжѓФиЊГпЉМе¶ВжЮЬзЫЄеРМпЉМеИЩи°®з§ЇжЬЯйЧіж≤°жЬЙеПСзФЯињЗеЖЩеЕ•жУНдљЬпЉМе∞±е∞ЖеОЯеЕИйБНеОЖзЪДзїУжЮЬињФеЫЮпЉМе¶ВжЮЬдЄНзЫЄеРМпЉМеИЩжККињЩдЄ™ињЗз®ЛеЖНйЗНе§НеБЪдЄАжђ°пЉМе¶ВжЮЬеЖНдЄНзЫЄеРМпЉМеИЩе∞±йЬАи¶Бе∞ЖжЙАжЬЙзЪДSegmentйГљйФБдљПпЉМзДґеРОдЄАдЄ™дЄАдЄ™йБНеОЖдЇЖпЉМеЕЈдљУзЪДеЃЮзО∞е§ІеЃґеПѓдї•зЬЛConcurrentHashMapзЪДжЇРз†БпЉМињЩйЗМе∞±дЄНиіідЇЖгАВ
 
PS. еОЯжЦЗеЬ®пЉЪJavaеєґеПСзЉЦз®ЛдєЛConcurrentHashMap
PSпЉЪжЬђзѓЗжЦЗзЂ†зЪДдєЯжПРдЊЫдЇЖPDFдЄЛиљљпЉЪconcurrentHashMap.pdf


- 2012-07-13 08:56
- жµПиІИ 1371
- иѓДиЃЇ(0)
- еИЖз±ї:зЉЦз®Лиѓ≠и®А
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
MyBatis-generatorдљњзФ®пЉМдЄЇExampleжЈїеК†еИЖй°µ
2017-11-01 16:10 4960жХ∞жНЃеЇУдЄЇMySQLгАВ1. еЬ®Exampleз±їйЗМпЉМеК†еЕ•дЄ§дЄ™еПШ ... -
дљњзФ®Spring MVCзїЯдЄАеЉВеЄЄе§ДзРЖеЃЮжИШ
2017-08-22 14:26 3361 жППињ∞¬†еЬ®J2EEй°єзЫЃзЪДеЉАе ... -
жЧ•ењЧзїДдїґзЪДеЕ≥з≥їжҐ≥зРЖпЉЪе¶ВдљХж≠£з°ЃдљњзФ®еЃГдїђ
2017-08-07 14:25 731иГМжЩѓ¬†¬†¬†¬† зФ±дЇОзО∞еЬ®еЉАжЇРж°ЖжЮґжЧ•зЫКдЄ∞еѓМпЉМе•ље§ЪеЉАжЇРж°ЖжЮґдљњзФ®зЪД ... -
JavaдЄ≠вАЬеЉХзФ®вАЭзЪДеЗ†зІНз±їеЮЛ
2017-07-18 17:09 611дЄА. ж¶Вињ∞пЉЪ еЉЇеЉХзФ®пЉИS ... -
SpringеТМMybatisжХіеРИжЧґжЧ†ж≥ХиѓїеПЦpropertiesзЪДе§ДзРЖжЦєж°И
2016-11-29 11:39 1741config.propertiesйЕНзљЃжЦЗдїґдњ°жБѓ ... -
ProtobufдљњзФ®
2016-07-12 11:49 2191ProtoBufзЪДеЃШжЦєдЄЛиљљеМЕеєґдЄНеМЕеРЂjarжЦЗдїґпЉМйЬАи¶БзФ®жИЈиЗ™ ... -
jmeterиѓїеПЦе§ЦйГ®йЕНзљЃжЦЗдїґ
2016-06-06 10:30 0йЕНзљЃжЦЗдїґжЬЙдЄ§з±їпЉЪ дЄАгАБиЈѓеЊДзЫЄеЕ≥йЕНзљЃжЦЗдїґпЉМеП™йЬАи¶БдЇЖиІ£жЄЕж•Ъjm ... -
@SuppressWarningsжКСеИґи≠¶еСКзЪДеЕ≥йФЃе≠Ч
2016-05-16 15:45 1962еЕ≥йФЃе≠Ч зФ®йАФ all to suppress a ... -
ApacheзЪДDbUtilsж°ЖжЮґе≠¶дє†
2016-04-01 19:47 758дЄАгАБcommons-dbutilsзЃАдїЛгАА гААгААco ... -
DubboдЄОZookeeperгАБSpringMVCжХіеРИеТМдљњзФ®пЉИиіЯиљљеЭЗи°°гАБеЃєйФЩпЉЙ
2016-03-30 20:13 705¬† дЇТиБФзљСзЪДеПСе±ХпЉМзљСзЂЩ ... -
Java GC иѓ¶иІ£
2016-03-30 19:54 7371гАБеЯЇжЬђеЫЮжФґзЃЧж≥Х пЉИ1пЉЙ еЉХзФ®иЃ°жХ∞пЉИReference ... -
JVMпЉИJavaиЩЪжЛЯжЬЇпЉЙдЉШеМЦе§ІеЕ®еТМж°ИдЊЛеЃЮжИШ
2016-03-30 19:53 500е†ЖеЖЕе≠ШиЃЊзљЃ еОЯзРЖ JVMе†ЖеЖЕе≠ШеИЖдЄЇ2еЭЧпЉЪPerman ... -
SpringдЇЛеК°зЪДдЉ†жТ≠и°МдЄЇеТМйЪФз¶їзЇІеИЂ
2016-02-20 22:32 910http://blog.csdn.net/paincupi ... -
javaдЄ≠дїАдєИжШѓbridge methodпЉИж°•жО•жЦєж≥ХпЉЙ
2016-01-31 19:19 558еЬ®зЬЛspring-mvcзЪДжЇРз†БзЪДжЧґеАЩпЉМзЬЛеИ∞еЬ®иІ£жЮРhandle ... -
@SuppressWarningsзЪДдљњзФ®гАБдљЬзФ®гАБзФ®ж≥Х
2016-01-06 16:45 1522еЬ®javaзЉЦиѓСињЗз®ЛдЄ≠дЉЪеЗЇзО∞еЊИе§Ъи≠¶еСКпЉМжЬЙеЊИе§ЪжШѓеЃЙеЕ®зЪДпЉМдљЖжШѓжѓПжђ° ... -
fastjsonйБЗеИ∞зЪДжЧ†йЩРйАТељТзЪДйЧЃйҐШ
2015-09-13 18:09 3983¬† ¬† ¬† ¬† fastjsonжШѓзФ®еПНе∞ДзЪДпЉМе¶ВжЮЬеЬ®еЃЮдљУз±їйЗМ ... -
ељУspring еЃєеЩ®еИЭеІЛеМЦеЃМжИРеРОжЙІи°МжЯРдЄ™жЦєж≥Х
2015-08-11 14:56 2262еЬ®еБЪwebй°єзЫЃеЉАеПСдЄ≠пЉМе∞§еЕґжШѓдЉБдЄЪзЇІеЇФзФ®еЉАеПСзЪДжЧґеАЩпЉМеЊАеЊАдЉЪеЬ®еЈ• ... -
javacеСљдї§еИЭз™•
2015-07-30 14:05 1952ж≥®пЉЪдї•дЄЛзЇҐиЙ≤ж†ЗиЃ∞зЪДеПВжХ∞еЬ®дЄЛжЦЗдЄ≠жЬЙжЙАиЃ≤иІ£гАВ зФ®ж≥Х: ja ... -
JDKеРДзЙИжЬђеЬ∞еЭАдЄЛиљљ
2015-07-17 13:09 13431. жАїеЬ∞еЭАпЉЪhttp://www.oracle.com/ ... -
jdk1.5-1.9жЦ∞зЙєжАІ
2015-07-17 13:02 17981.51.иЗ™еК®и£ЕзЃ±дЄОжЛЖзЃ±пЉЪ2.жЮЪдЄЊ(еЄЄзФ®жЭ•иЃЊиЃ°еНХдЊЛж®°еЉП)3. ...
зЫЄеЕ≥жО®иНР
иІ£жЮРconcurrenthashmapзЪДжЇРз†БпЉМе≠¶дє†е§ЪзЇњз®ЛзЪДжАЭжГ≥
java7-8дЄ≠зЪД HashMapеТМConcurrentHashMapеЕ®иІ£жЮР
java7-8дЄ≠зЪД HashMapеТМConcurrentHashMapеЕ®иІ£жЮР е¶ВжЮЬдљ†жГ≥дЇЖиІ£еЇХе±ВзЪДйАїиЊСе∞±жЭ•зЬЛзЬЛеРІ
ConcurrentHashMapеЕЈдљУжШѓжАОдєИеЃЮзО∞зЇњз®ЛеЃЙеЕ®зЪДеСҐпЉМиВѓеЃЪдЄНеПѓиГљжШѓжѓПдЄ™жЦєж≥ХеК†synchronizedпЉМйВ£ж†Је∞±еПШжИРдЇЖHashTableгАВ
HashMap& ConcurrentHashMap жЈ±еЇ¶иІ£жЮР
ConcurrentHashMapжЇРз†БзЇІеИЂзЪДйЭҐиѓХиІ£жЮРпЉМйАВеРИ0~2еєізЪДдЇЇеСШпЉМйЩДжЇРз†БиІ£иѓїпЉМдЄЛиљљеН≥еПѓжЛњеИ∞mdзЪДжЇРжЦЗж°£
дїК姩е∞ПзЉЦе∞±дЄЇе§ІеЃґеИЖдЇЂдЄАзѓЗеЕ≥дЇОJavaжЇРз†БиІ£жЮРConcurrentHashMapзЪДеИЭеІЛеМЦпЉМе∞ПзЉЦиІЙеЊЧеЖЕеЃєжМЇдЄНйФЩзЪДпЉМзО∞еЬ®еИЖдЇЂзїЩе§ІеЃґпЉМеЕЈжЬЙеЊИе•љзЪДеПВиАГдїЈеАЉпЉМйЬАи¶БзЪДжЬЛеПЛдЄАиµЈиЈЯйЪПе∞ПзЉЦжЭ•зЬЛзЬЛеРІ
дЄЛйЭҐе∞ПзЉЦе∞±дЄЇе§ІеЃґеЄ¶жЭ•дЄАзѓЗеЯЇдЇОJavaеєґеПСеЃєеЩ®ConcurrentHashMap#putжЦєж≥ХиІ£жЮРгАВе∞ПзЉЦиІЙеЊЧжМЇдЄНйФЩзЪДпЉМзО∞еЬ®е∞±еИЖдЇЂзїЩе§ІеЃґпЉМдєЯзїЩе§ІеЃґеБЪдЄ™еПВиАГгАВдЄАиµЈиЈЯйЪПе∞ПзЉЦињЗжЭ•зЬЛзЬЛеРІ
зЇњз®ЛеЃЙеЕ®зЪД Map вАУ ConcurrentHashMapпЉМиЃ©жИСдїђдЄАиµЈз†Фз©ґеТМ HashMap зЫЄжѓФжЬЙдљХеЈЃеЉВпЉМдЄЇдљХиГљдњЭиѓБзЇњз®ЛеЃЙеЕ®еСҐ. 1 зїІжЙњдљУз≥ї [е§ЦйУЊеЫЊзЙЗиљђе≠Ш姱賕,жЇРзЂЩеПѓиГљжЬЙйШ≤зЫЧйУЊжЬЇеИґ,еїЇиЃЃе∞ЖеЫЊзЙЗдњЭе≠ШдЄЛжЭ•зЫіжО•дЄКдЉ†(img-gkf7KyhC-...
дЄКеЫЊдЄ≠пЉМжѓПдЄ™зїњиЙ≤зЪДеЃЮдљУжШѓеµМе•Чз±ї Entry зЪДеЃЮдЊЛпЉМEntry еМЕеРЂеЫЫдЄ™е±ЮжАІпЉЪkey, value, hash еАЉеТМзФ®дЇОеНХеРСйУЊи°®зЪДcapacityпЉЪељУеЙНжХ∞зїДеЃєйЗП
JavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙпЉМJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†...
JavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙпЉМJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†еЃЭеЕЄпЉИжЉЂзФїзЙИпЉЙJavaеєґеПСзЉЦз®Ле≠¶дє†...
HashMapгАБConcurrentHashMapжЇРз†БзЇІиІ£иѓїпЉМеєґдЄФеѓєжѓФдЇЖJDK7еТМ8еЃЮзО∞зЪДдЄНеРМпЉМињЫи°МдЇЖе§ІйЗПзЪДиІ£йЗКпЉМзїУеРИдЇЖе§ЪдЄ™е≠¶дє†иІЖйҐС
javaжЙАжЬЙйЫЖеРИз±їеЇХе±ВжЇРз†БиІ£жЮРж±ЗжАїпЉМеМЕжЛђArrayListгАБHashMapгАБHashSetгАБLinkedListгАБTreeMapгАБHashSetгАБConcurrentHashMapз≠ЙйЫЖеРИж°ЖжЮґзЪДеЇХе±ВеЃЮзО∞жЇРз†Бе§ІзЩљиѓЭиІ£иѓїгАВ
еєґеПСеЃєеЩ®ConcurrentHashMapеОЯзРЖдЄОдљњзФ®.mp4 зЇњз®Л汆зЪДеОЯзРЖдЄОдљњзФ®.mp4 Executorж°ЖжЮґиѓ¶иІ£.mp4 еЃЮжИШпЉЪзЃАжШУwebжЬНеК°еЩ®пЉИдЄАпЉЙ.mp4 еЃЮжИШпЉЪзЃАжШУwebжЬНеК°еЩ®пЉИдЇМпЉЙ.mp4 JDK8зЪДжЦ∞еҐЮеОЯе≠РжУНдљЬз±їLongAddrеОЯзРЖдЄОдљњзФ®.mp4 JDK8жЦ∞еҐЮйФБ...
еЕґдЄ≠жЬНеК°зЂѓдЄЇиІ£еЖ≥е§ЪзЇњз®ЛжУНдљЬеЕ±дЇЂиµДжЇРпЉМз°ЃдњЭзЇњз®ЛеЃЙеЕ®жСТеЉГиµДжЇРжґИиАЧе§ІзЪДSynchronizedдљњзФ®ConcurrentHashMapе≠ШжФЊSocketеѓєи±°гАВ жЬНеК°зЂѓпЉЪ пЉИ1пЉЙињЮжО•еЃҐжИЈзЂѓпЉЪеЃЮзО∞дЄОеЃҐжИЈзЂѓзЪДSocketйАЪдњ°гАВ пЉИ2пЉЙзЃ°зРЖеЃҐжИЈзЂѓпЉЪеЃЮзО∞йАЪињЗзЇњз®Л汆...
08HashMapдЄОConcurrenthashMapжЇРз†БиІ£иѓї 09MySQLжЈ±еЇ¶еОЯзРЖиІ£жЮР 10NettyжЈ±еЇ¶жЇРз†БиІ£иѓї 11SpringCloudеЊЃжЬНеК°ж°ЖжЮґжЇРз†БиІ£иѓї 12ељїеЇХжРЮжЗВеИЖеЄГеЉПйФБжЮґжЮДиЃЊиЃ°еОЯзРЖ 13еИЖеЄГеЉПжХ∞жНЃдЄАиЗіжАІиЃЊиЃ°еОЯзРЖ 14еИЖеЄГеЉПжґИжБѓдЄ≠йЧідїґ 15еЃЮжИШжЦ∞йЫґеФЃ...
еМЕеРЂдЇЖжС©ж†єйЭҐиѓХзЪДжКАжЬѓи¶БзВєпЉМжґЙеПКJVMжЮґжЮДпЉМеЖЕе≠ШеЫЮжФґпЉМClassloaderз≠ЙJDKеЇХе±ВжКАжЬѓпЉМдєЯеМЕжЛђеГПHashMap,ConcurrentHashMap,ObjectзЇњз®ЛеРМж≠•з≠ЙAPIзЪДиІ£иѓїпЉМињШжґЙеПКдЇЖSpring AOPеОЯзРЖиІ£жЮРз≠Йж°ЖжЮґжКАжЬѓгАВ
зђђ51иКВеєґеПСеЃєеЩ®ConcurrentHashMapеОЯзРЖдЄОдљњзФ®00:38:22еИЖйТЯ | зђђ52иКВзЇњз®Л汆зЪДеОЯзРЖдЄОдљњзФ®00:42:49еИЖйТЯ | зђђ53иКВExecutorж°ЖжЮґиѓ¶иІ£00:36:54еИЖйТЯ | зђђ54иКВеЃЮжИШпЉЪзЃАжШУwebжЬНеК°еЩ®пЉИдЄАпЉЙ00:55:34еИЖйТЯ | зђђ55иКВеЃЮжИШпЉЪзЃАжШУ...